十多年前,谷歌才意识到,在支持机器学习算法所需的张量处理方面,它需要控制自己的硬件命运。几周前,谷歌在其年度 I/O 大会上宣布了第六代张量处理单元 ,但目前关于它们的问题仍然多于答案。
这很好,因为我们预计谷歌要到今年第四季度才会使用 TPU v6 设备安装超级计算机系统。但我们是计算引擎和系统架构的急切观察者,因此试图弄清楚这些 TPU v6 引擎的显著特点以及它们与前几代 TPU 相比在性价比方面的表现如何。因此,我们首次尝试对 TPU 系列进行比较分析,该系列涵盖了 2015 年首次部署的 TPU v1 以及包括新 TPU v6 在内的八种不同的 TPU 设备。
TPU 引擎及其使用系统不仅仅是与 Nvidia 协商 GPU 式矩阵数学引擎更好定价的一种方式。TPU 还是一种推动混合精度、矩阵和串行处理设计、内存子系统以及 AI 训练和推理系统互连基础研究的方式。这为 Google 提供了一个基准,可以在此基础上比较基于 Nvidia 和 AMD GPU 的系统、基于 Intel Gaudi 加速器的系统以及基于 SambaNova Systems、Cerebras Systems、Tenstorrent 等公司的专用系统。
代号为“Trillium”的第六代 TPU 以一种俗称的木百合命名,这种植物在美国东南部的阿巴拉契亚山脉最为密集。TPU v6 很可能是一对设备中的第一款,其中一款在推理工作负载方面更胜一筹,而部署这类工作负载的成本非常高昂,即使对于像谷歌这样的富有公司来说也是如此。TPU v4i 和 TPU v5e 设备都是 TPU v4 和 TPUv5 架构的定制版本,经过调整,可实现 AI 推理的性价比。
关于 TPU v6 设备的细节非常少,但我们推测最终——意味着在该设备在 Google Cloud 上投入生产并可供外部客户租用后——TPU v6 芯片的规格将在 TPU 系统架构文档中发布,该文档记录了从 TPU v2 到 TPU v5e 的规格。
谷歌在其关于初始 Trillium 设备的博客文章中表示,与 TPU v5e 相比,TPU v6 的每芯片峰值性能高出 4.7 倍,HBM 内存容量和 HBM 内存带宽也高出两倍。连接 TPU v6 芯片的芯片间互连 带宽也增加了一倍。Trillium 设备还具有第三代 SparseCore 加速功能,用于处理常用于排名和推荐算法的嵌入 — — 这种算法推动了谷歌的搜索和广告业务,并且将越来越多地推动主流企业的业务。
Trillium 芯片的矩阵乘法单元 比前四代芯片更大,前四代芯片使用的是 128×128 矩阵,但谷歌没有透露具体大小。TPU v1 芯片的核心使用的是 256×256 矩阵,我们认为谷歌可能已经恢复了这种格式,并找到了一种高效地将其加倍的方法。谷歌创建 192×192 矩阵的可能性很小,但我们对此表示怀疑。它违反了我们的对称感。
谷歌补充说,Trillium 设备的能效比 TPU v5e 芯片高出 67%,并且可以在松散耦合的系统中组装成 256 个设备的块,以运行 AI 工作负载。据我们所知,TPU v6 设备不支持 64 位或 32 位浮点数学。TPU v2 和 TPU v3 芯片支持 16 位 BrainFloat 格式进行处理,而 TPU v1 仅支持 INT8 整数格式。对于 TPU v4 和 TPU v5 系列设备,MXU 支持 INT8和 BF16。我们确信 TPU v6 设备将支持 INT8 和 BF16,但 Trillium 也有可能支持较低的八位和四位格式。
在我们可靠的电子表格中仔细考虑了这些问题之后,我们得出了 Trillium 设备可能的进给、速度和定价如下:
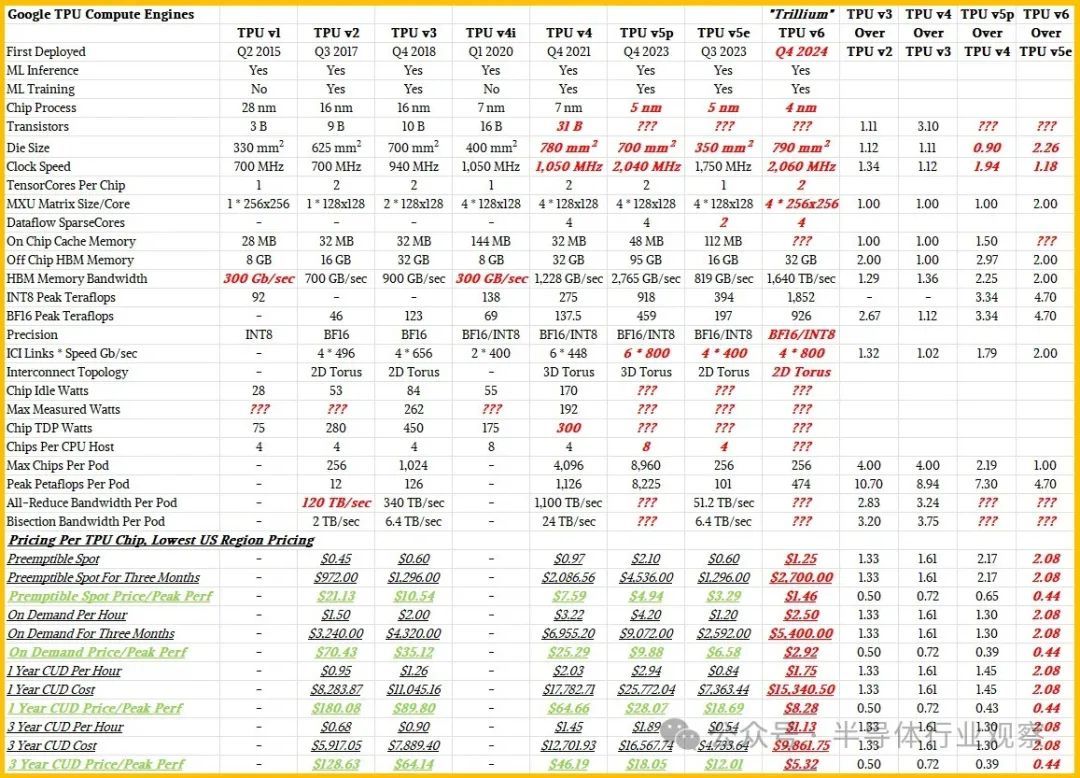
与往常一样,以粗体红色斜体表示的项目是The Next Platform的估计。
Google 并未统一提供所有 TPU 的馈送和速度,而这更令人好奇。TPU v4i pod 的规模从未披露,其定价也未披露。较新的 TPU 缺少芯片尺寸和工艺节点,也缺少一些基本热量,例如最大和空闲功率。我们可以计算值的地方,我们做到了,这些数字以黑色显示,因为计算不是估算。
TPU 的进给和速度以及它们的主机和 pod 可扩展性都很有趣,但我们还认为价格/性能随时间的趋势同样重要,而且我们确实有这方面的数据。
我们可以告诉您的第一件事是,自从我们在2022 年 10 月深入研究 TPU v4 架构以来,Google 实际上已经提高了 TPU v2 容量的价格。坦率地说,这些设备现在已经有七年的历史了,与较新的 TPU 相比,性价比非常低,我们很惊讶 Google Cloud 上 TPU v2 容量的价格并没有低很多。
我们猜测,有了 TPU v6,谷歌实际上会将租用这些设备的价格提高 2 倍多一点,而由此产生的 Trillium 实例仍将比谷歌云上的 TPU v5e 实例提供 2.3 倍以上的性价比,比 TPU v5p 提供 3.4 倍的性价比,而 TPU v5p 是一种更重的设备,虽然它可以同时完成 AI 训练和 AI 推理,但它更适合 AI 训练。
重点是,TPU v6 的性能好太多了,以至于 Google 可以对每台设备收取更高的费用,同时仍能为客户提供更优惠的 AI 训练和推理吞吐量。如果有 TPU v6e,正如我们所猜测的那样,推理成本可能会更低,如果有 TPU v6p,训练成本可能会进一步下降。
如果谷歌的定价与我们对 Trillium 实例的预期一致,那么 TPU 实例的成本将随着时间的推移而降低,这是另一个有趣的趋势。对于可抢占实例,在 TPU 芯片上可用的最精细数据分辨率下,2017 年的 TPU v2 和今年的 TPU v4 之间的每单位性能成本下降了 14.5 倍。按需定价将下降 24.2 倍,一年期预留实例下降 21.7 倍,三年期预留实例下降 24.2 倍。
我们将拭目以待。一旦我们了解更多信息,我们将告知您,我们很乐意使用自研的加速器和云端 GPU 进行竞争分析。



